
Introduction to Cassandra
What is Cassandra?
Apache Cassandra is an open source, distributed, NoSQL database. It presents a partitioned wide column storage model with eventually consistent semantics.
Apache Cassandra was initially designed at Facebook using a staged event-driven architecture (SEDA) to implement a combination of Amazon’s Dynamo distributed storage and replication techniques combined with Google’s Bigtable data and storage engine model. Dynamo and Bigtable were both developed to meet emerging requirements for scalable, reliable, and highly available storage systems, but each had areas that could be improved.
Cassandra was designed as a best in class combination of both systems to meet emerging large scale, both in data footprint and query volume, storage requirements. As applications began to require full global replication and always available low-latency reads and writes, it became imperative to design a new kind of database model as the relational database systems of the time struggled to meet the new requirements of global scale applications.
How does Cassandra work?
Apache Cassandra is a peer-to-peer system. Its distribution design is modelled on Amazon’s DynamoDB, and its data model is based on Google’s Big Table.
The basic architecture consists of a cluster of nodes, any and all of which can accept a read or write request. This is a key aspect of its architecture, as there are no master nodes. Instead, all nodes communicate equally.
While nodes are the specific location where data lives on a cluster, the cluster is the complete set of data centres where all data is stored for processing. Related nodes are grouped together in data centres. This type of structure is built for scalability and when additional space is needed, nodes can simply be added. The result is that the system is easy to expand, built for volume, and made to handle concurrent users across an entire system.
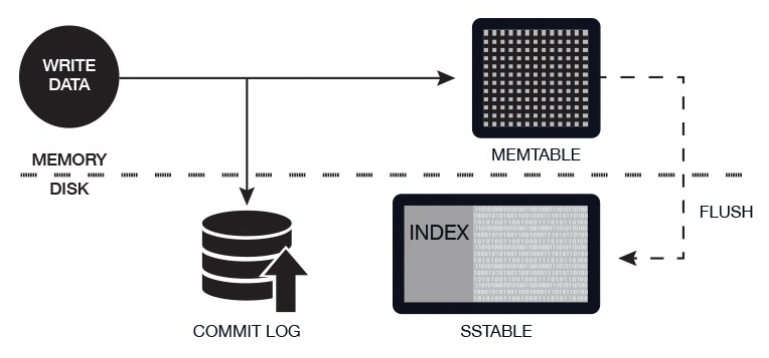
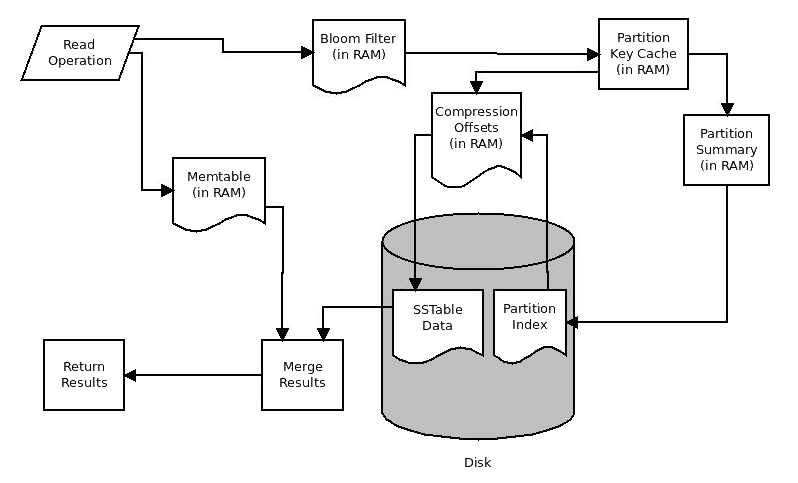
Its structure also allows for data protection. To help ensure data integrity, Cassandra has a commit log. This is a backup method and all data is written to the commit log to ensure data is not lost. The data is then indexed and written to a memtable. The memtable is simply a data structure in the memory where Cassandra writes. There is one active memtable per table.
When memtables reach their threshold, they are flushed on a disk and become immutable SSTables. More simply, this means that when the commit log is full, it triggers a flush where the contents of memtables are written to SSTables. The commit log is an important aspect of Cassandra’s architecture because it offers a failsafe method to protect data and to provide data integrity.
Cassandra Query Language?
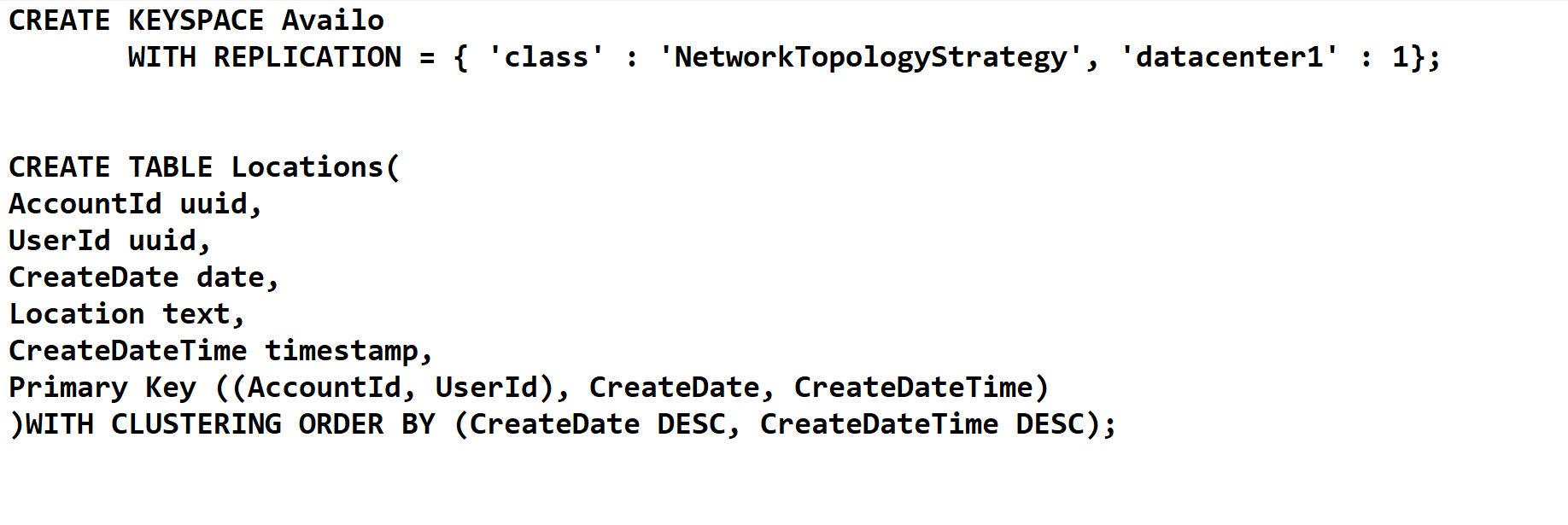
Cassandra provides the Cassandra Query Language (CQL), an SQL-like language, to create and update database schema and access data. CQL allows users to organize data within a cluster of Cassandra nodes using:
⦁ Keyspace: defines how a dataset is replicated, for example in which datacentres and how many copies. Keyspaces contain tables.
⦁ Table: defines the typed schema for a collection of partitions. Cassandra tables have flexible addition of new columns to tables with zero downtime. Tables contain partitions, which contain partitions, which contain columns.
⦁ Partition: defines the mandatory part of the primary key all rows in Cassandra must have. All performant queries supply the partition key in the query.
⦁ Row: contains a collection of columns identified by a unique primary key made up of the partition key and optionally additional clustering keys.
⦁ Column: A single datum with a type which belong to a row.
Pros
- Cassandra is solving the problem of distributed and scalable systems, and it is built to cope with data management challenges of modern business.
- Cassandra is decentralized system - There is no single point of failure, if minimum required setup for cluster is present - every node in the cluster has the same role, and every node can service any request. Replication strategies can be configured. It is possible to add new nodes to server cluster very easy. Also, if one node fails, data can be retrieved from some of the other nodes (redundancy can be tuned). It is especially suitable for multiple data-center deployment, redundancy, failover, and disaster recovery, with possibility of replication across multiple data centers.
- Very important, Cassandra has Hadoop integration, with MapReduce support, also for Apache Pig and Apache Hive.
Cons
- This level of flexibility has its price.
- there is no referential integrity - there is no concept of JOIN connections in Cassandra.
- querying options for retrieving data are very limited.
- sorting of data is a design decision; it can be done through one of predefined ways; data can be retrieved back in same order; that is all - there is no things like ORDER BY, GROUP BY
- denormalization is good; you want to normalize your data and to have redundancy (big no-no according to Codd) - data is stored in a way that it will be retrieved.
- different database design: in RDBMS we think about data modeling first, and after that we create queries; here, we think first about most common queries, and after that, data is being modeled around those queries.
Summary
NoSQL database models will not and cannot completely replace RDBMS technology, but importance of NoSQL will grow because of scale, flexibility, and ease-of-use. We are dealing with more and more of data; we want durable and fault-tolerant applications; we want apps that scale and apps that are fast. Because all of these, NoSQL will be around us more and more, and it’s definitely technology worth exploring
Add new comment











